
How to Stop Underestimating Uncertainty in Your Marketing Data
Panel data is everywhere in data science. But observations are not independent, so we have to be careful.

Panel data is everywhere in data science—but many models assume independence when observations are actually correlated over time. Ignore this in simulations, and your confidence intervals will be wrong.
Let’s take a simple example:
We want to measure the impact of increasing ad spend in Seattle, but not in Portland.
We observe both cities before and after the marketing change. But here’s the problem:
Seattle appears multiple times in the data.
These data points aren’t independent. For example, if a GenAI-driven sales boom starts in Seattle, its impact persists over time, making observations correlated.
So how do we get valid confidence intervals while respecting these dependencies?
Use the Block Bootstrap
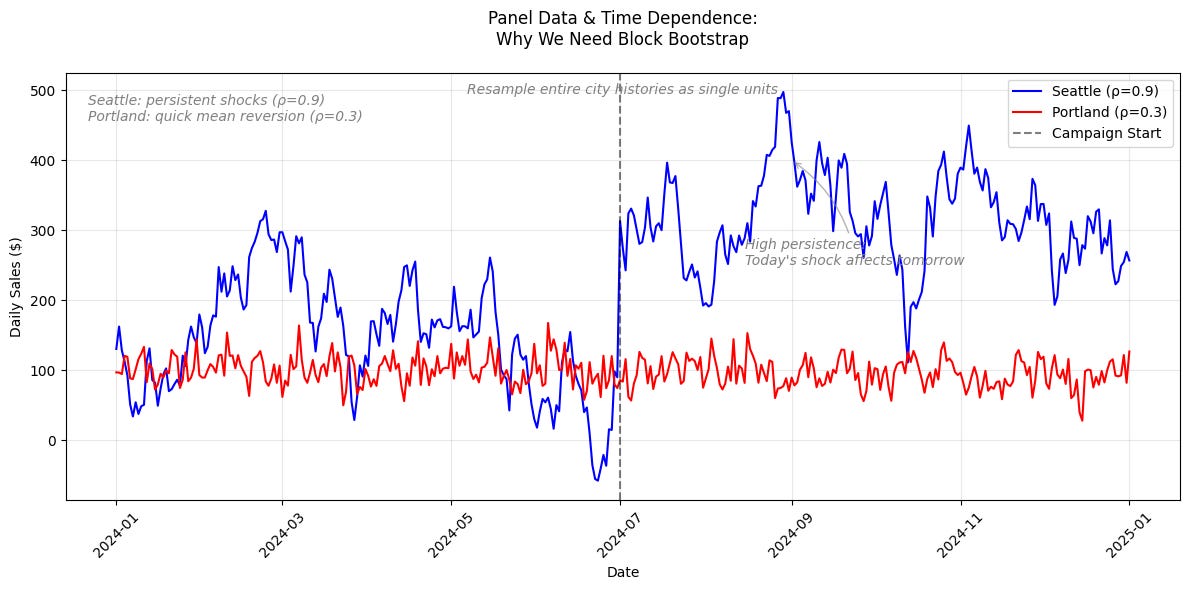
Standard bootstrapping would underestimate uncertainty by treating correlated observations as independent.
Instead of resampling individual observations, resample entire cities to preserve time dependence:
Randomly draw cities (with replacement).
Keep all time series data for each drawn city.
Compute your estimate.
Repeat many times to get a valid confidence interval.
Key insight: By resampling entire cities, we respect the dependency structure in the data and get valid confidence intervals.