
Validating Causal Models Is Hard—But Here’s a Trick
A practical way to validate causal targeting models for marketing, personalization, and more.

Prediction models? Easy to validate. A picture is of a cat or a dog. ✅
Causal models. Hard. We want to compare two parallel universes: what happens with and without a marketing campaign. But we can’t observe both. ❌
Enter causal targeting models, which predict how each person will respond to a campaign. These models have a unique advantage: the richness of individual predictions creates a structure we can use for validation.
The Trick
A good model should rank individuals well—those predicted to respond most should actually respond better. But how do we check that?
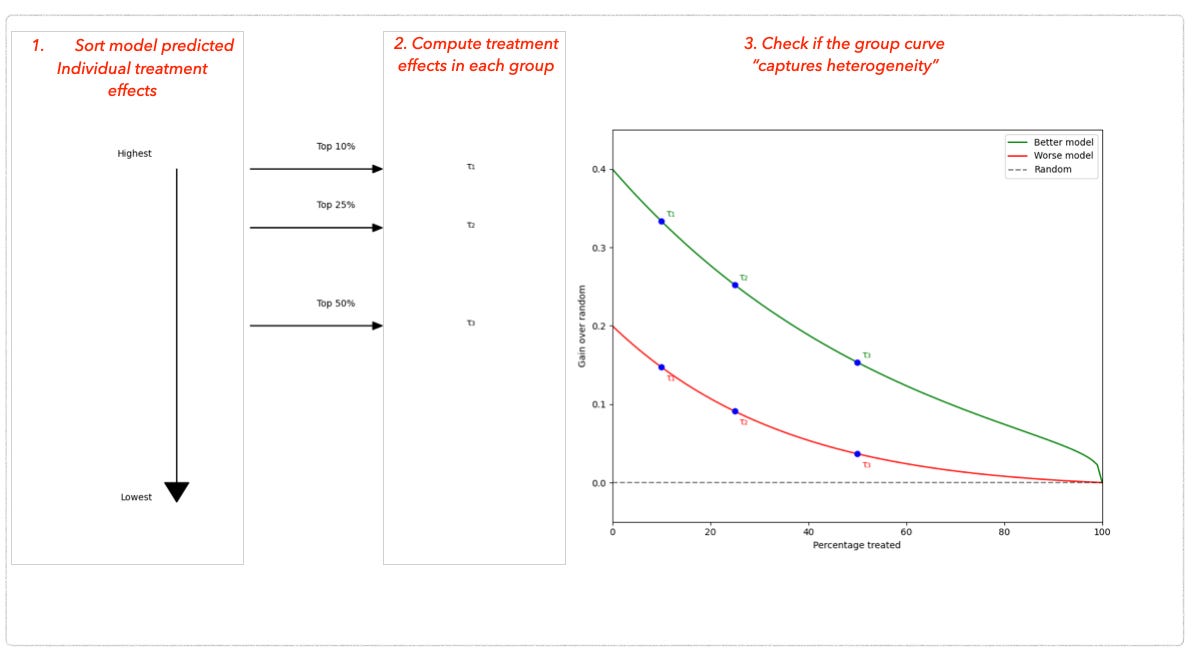
Here’s the simple recipe:
Sort and Group: Sort predicted individual treatment effects and split them into groups (e.g., top 10%, top 25%).
Compute Group Effects: Each group contains people who received the campaign (treatment) and those who didn’t (control). Compare their outcomes to compute the “true” effects for each group.
Validate: The group effects should “behave nicely.” For example, the top group should respond significantly better than everyone else, capturing heterogeneity in treatment effects.
Why This Matters
This method gives you a structured way to validate causal targeting models—even without access to counterfactuals.
It’s essential for personalization:
Marketing: Who should get the next campaign?
Sustainability: Who responds to green initiatives?
Some Useful Links
Want to try it yourself? Check out this notebook from Microsoft Research, the creators of EconML, one of GitHub’s top causal inference packages.
The theory: Dive into Radcliffe’s 2007 paper, which proposed this approach.
This is basically Uplift Modeling, right? Predicting who is most persuadable to a given campaign? Very cool.